NLP - Transformer
Contents
- Former RNNs
- Transformers
- Multi-Head Attention
- Comparison of Computational Resources
- Block-Based Model
- Model Speicific Techniques
- Decoder
- Model Performane
Transformer adopts the attention method of Seq2Seq with attention without the division of the encoder and the decoder. Concise model helps faster learning, and by stacking queries into a matrix, the model further boosts the computational speed, still obviating the long term dependency problem and considering the future input sequences.
1. Former RNNs
- RNN: the information propagates through multiple mathematic transformations, casuing long term dependency problem
- Bi-directional RNN: long term dependency problem still present, but each output can consider the words that will come after the present time step
- Transformer even solves the long term dependency problem
2. Transformer
- Uses only the attention model from Seq2Seq as the main model
- General Structure

a. Key Components
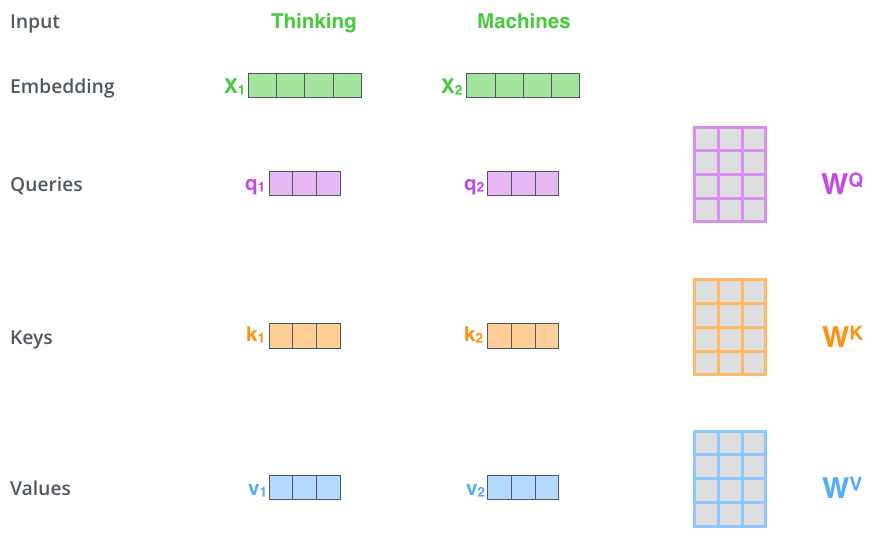
- Query Vector: a vector transformed from the input vector of the corresponding time period via
to calculate the weights of each value vector in producing the final output
.
- Key Vector: vector transformed from all input vectors via the matrix product with
. The model will calculate the weight for each value vector by doing inner product of a query vector and key vectors.
- Value Vector: input vectors from all time period are transformed via to produce value vector
. The weighted sum of these vectors is the output vector.
b. Detailed Process
- The model trains matrix
- We first calculate the weight, where n is the length of the entire sequence. The result is probability (or ratio) that adds up to 1
- Multiplying each element of the weight vector with the corresponding value vector, we get the output vector
(output vector for the ith time period)
- Entire process simplified, we get
- We have multiple query vectors, so if we stack them and make matrix
, the whole process is simplified as follows
or equivalently,
- Matrix multiplication is well optimized, making the self-attention model even faster
- The model has huge improvement from the previous RNNs, also because the inputs from long period ago are nto subject to multiple transformations. All inputs have equal path to the outpiut of whenever time period, solving the long term dependency problem.
- On top of that, the sequence can consider the inputs that would normally appear later, allowing more information of the context to be channelled into the model.
c. Scaling the Dot Product
- Method:
- Rationale: let’s assume the elements of
are mutually independent and follows a normal distribution with mean 0 and variance 1. The variance of
is
, the dimension of the matrices. Having huge variance is not good for training because then the weights would vary significantly, meaning that the output would reflect only some of the value vectors. To prevent this, the model divides
3. Multi-Head Attention

- Need: each attention layer specializes in encoding the input sequence. For example, a layer could specialize in understanding the relationship between a noun and its modifers.
4. Comparison of Computational Resources

is sequence length
is dimension of representation
is the kernel size
is the size of neighborhood
- Self attention model requires larger number of computations, but the type of computation is matrix multiplication, thus requires less total time for training. In contrast, the recurrent model requires less number of computations, but the operation is sequential; the model has a series connection, making the total training time longer.
5. Block-Based Model

- Residual connection: Propagates x to after the multi-head attention layer. The layer is trained to learn the residual,
, not
- Layer normalization
6. Model Speicific Techniques
a. Normalization

- Affine Transformation:
. The parameters are all trainable.
- Batch Norm: for each pertaining node, normalize the values from all batches collectively and affine transform.
- Layer Norm: normalize each words vectors, then affine transform each sequence vector like below.

b. Positional Encoding
- Need: transformer produces the same output wherever the words are place, as long as the input words are the same. See the structure of transformer to understand.
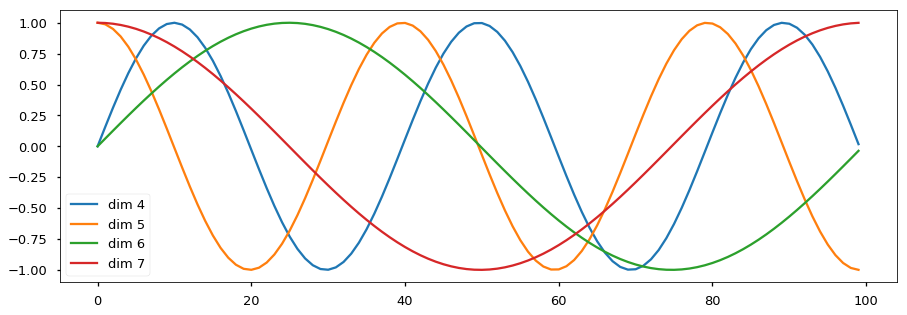
Image Source - Use sinusoidal functions, for example, use sine functions for the even dimensions, and consine for the others, with different frequencies for all dimensions and them to input vectors.
c. Warm-up Learning Rate Scheduler
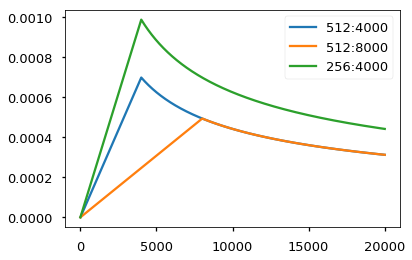
- Offsets initial large gradient with small learning rate. The apex in the middle further pushes the model that could have settled for a local minimun.
7. Decoder
When do we need to perform tasks that require additional sequence input, such as translation, we use models with decoder.
a. Detailed Process
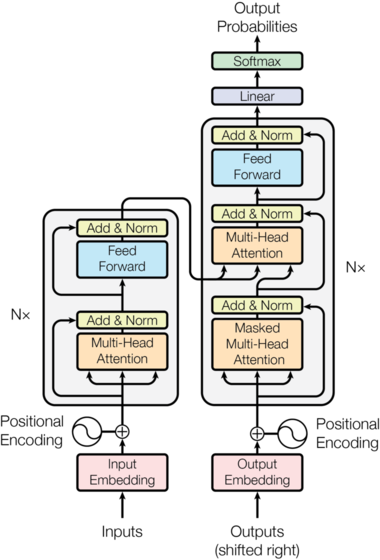
- The query vector is from the decoder, and the key vector and the value vector is the output of the encoder
- Use Masked decoder self-attention to produce query vector
b. Masked Self-Attention
- At the inference stage, the model does not have any access to inputs from the later sequence. To emulate such environment in the training process, the model has to block the access to the inputs from later sequence.
- This can be done by adequately masking the output from
as below.

Image Source - Purple region is the elements of the matrix that the value is set as 0.
- Each row mathematically expressed,
- Simply put,
8. Model Performance
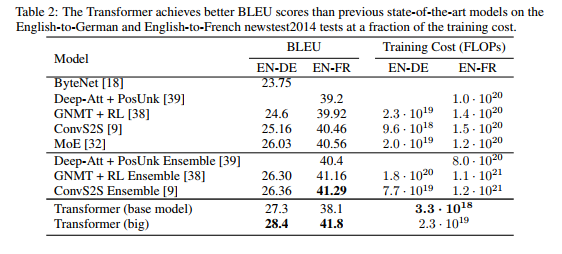
- Reduces the training cost significantly
- BLEU score surpassed all SOTA models at year 2014 for the given task